






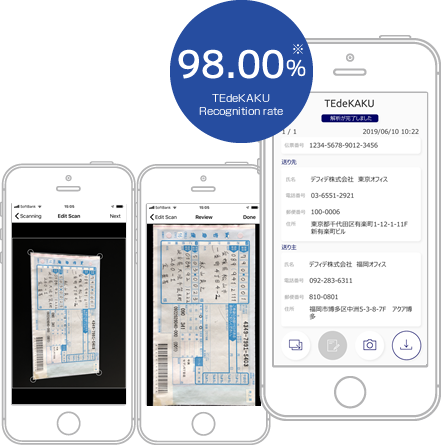
Features
TEdeKAKU automatically recognizes the document type and the information described in the document. It converts the captured handwritten document into digital data using deep CNN/OCR and AI. It can also self-learn through user corrections as to derive the correct analysis result.





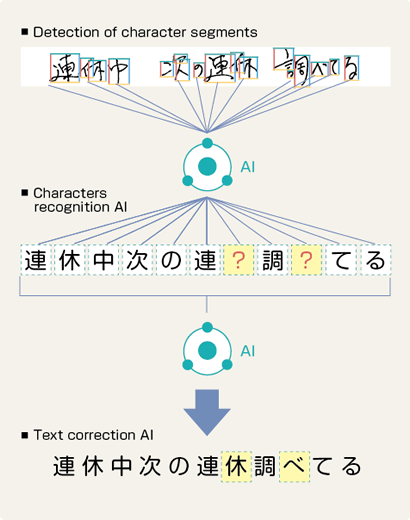
In this step, character segments are detected using image processing, labeling processing,
and shape analysis processing.
In addition, meaningful character elements are detected by combining these parts stepwise.

In this step, optical character recognition (OCR) is performed using a convolutional neural network (CNN) learning data of kanji and hiragana handwritten characters.

Finally, by using a recursive neural network (RNN) that uses a model that divides a document into an arbitrary number of consecutive characters, incorrect characters are detected and adapted to correct sentences.
AI handwritten Japanese character recognition based on image, speech
pattern and
grammar recognition.
- TEGAKI Recognition Accuracy-
Go here if you want
to know more
about TEdeKAKU