

PROFILE
01
自然言語処理や計算言語学を専門に研究する

―本日は小町先生の研究内容とソーシャル・データサイエンス学部・研究科を立ち上げになられた背景、技術現場の現状と限界、言語の文化資源、実社会での応用とリスク、教育人材と若い世代に対するメッセージ、未来展望などのテーマに基づいて質問をさせてください。まずは、小町先生の研究内容・専門分野からご紹介いただければと思います。
私の研究分野は、自然言語処理(NLP:Natural Language Processing。人間が日常的に使っている言語をコンピュータで処理・分析・生成する技術)や計算言語学(自然言語を計算可能な形式で理解・処理する研究分野)などと呼ばれる分野です。コンピュータを使って人間が話したり、書いたりしているような言語を理解したり、テキストを生成したりするような研究を手掛けています。
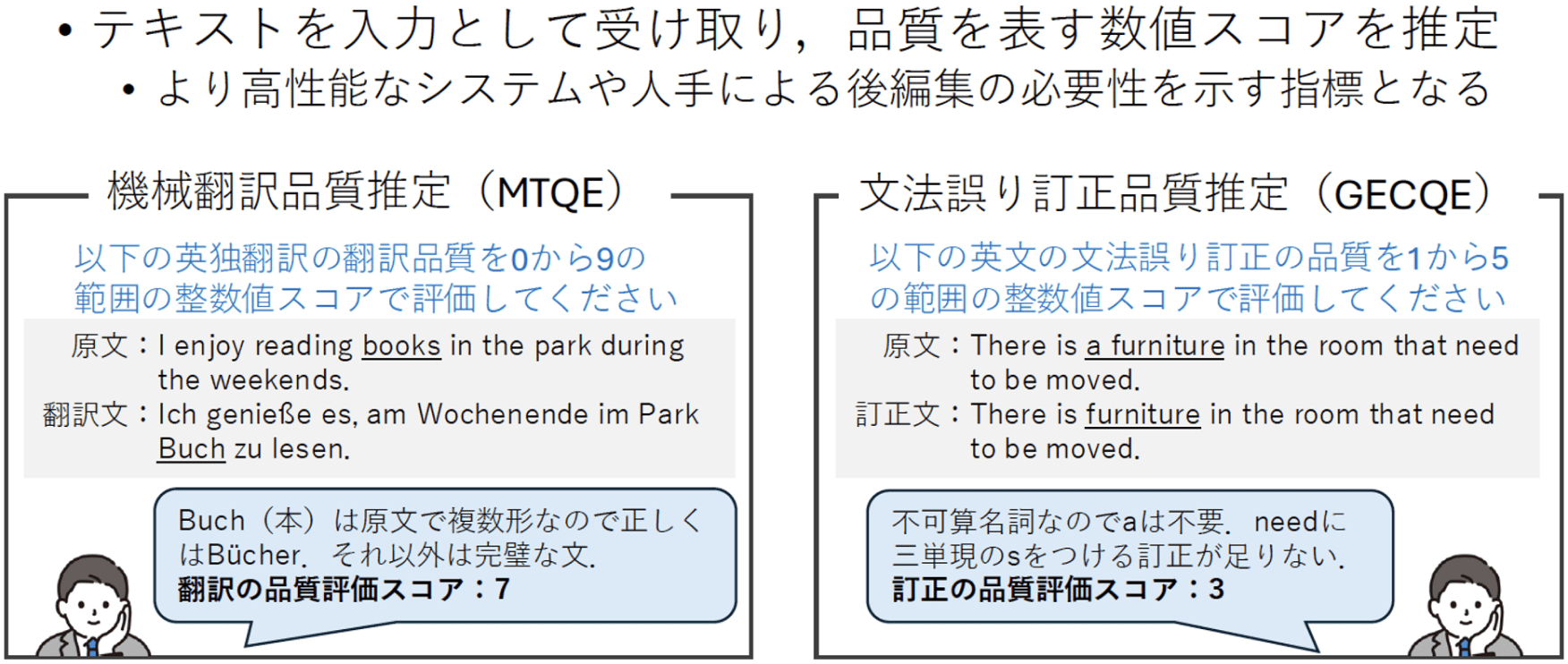
例えば、機械翻訳(ある自然言語を別の自然言語に翻訳する作業を自動化したシステム)は英語を入れたら、日本語に翻訳し書き出したりします。あるいは、文書要約は長い文書を入れたら短い要約を提示します。最近取り組んでいたのは、文法の誤り訂正です。文法的な誤りがあったら、そこを訂正することに取り組んでいました。直近ではテキスト平易化といって、分かりにくい文章を分かりやすい文章に言い換えることもやっています。入力か出力にテキストが介在するようなもの全部が、私の研究対象になっているとご理解いただければと思います。
特に、この5年ぐらい研究の中心として取り組んでいるのは、テキストの評価です。どういうふうに、人間が「この文章は良い文章だ」と思うのかどうかみたいなものです。あとは、人間が「良い文章だ」と思っているものの、実は何か間違っている。しかし、人間は間違っていても悪い文章と思わないとかですね。昨今はそういう文章が、色々な大規模言語モデル(LLM。大量のテキストデータを用いて構築された巨大な自然言語処理モデル)によって生成されていて、世の中に溢れています。そこで、そういう人間の好みのバイアスみたいなものがどこにあるのかにも興味があります。
それとは別に直近でいうと、ここ100年とか、ここ10年での言語の変化です。単語の使われ方が変わって来ています。例えば、ゲイという単語は、昔は楽しいという意味でした。それが、近年はLGBT(セクシャルマイノリティ)の意味に変わってきたりしています。そういう意味の変化がどういうふうにどの単語で起きているのかも興味を持って取り組んでいます。
02
データサイエンスは調理器具。何を題材にするかが重要
%20(1).webp)
―一橋大学ソーシャル・データサイエンス学部・研究科の開設趣旨もご説明いただけますか。
一橋大学ソーシャル・データサイエンス学部・研究科は、2023年に設立されました。そのタイミングで、私は都立大学から移ってきました。ソーシャル・データサイエンスとは、ソーシャルサイエンス(社会科学)とデータサイエンス(統計学、情報工学、機械学習など、様々な領域の手法を用いて有意義な知見を引き出すための研究分野)の両方ともやりますという気持ちで作られている学部・研究科です、
なぜ、そうしているのかというと、日本全国でデータサイエンスに関する学部や学科が沢山誕生してきているものの、データサイエンスは、要は調理器具、包丁みたいなもので、何を題材に料理するのかが大事になってきます。食材抜きに何かひたすら包丁だけ研いでいますというのでは、やはりその良さが活きません。なので、一橋大学としては敢えてデータサイエンス学部・研究科を作るにあたり、一番の強みである社会科学ですね。経済学や法学とか社会学、そういうものにデータサイエンスの手法を使いたいという想いをカタチにしました。それぞれの社会科学で使うデータの中に、テキストが非常に多く含まれています。なので、そのテキストを使った社会科学に対するデータサイエンス的なアプローチでの貢献が、自分の役割となります。
自然言語処理は本来、割りとエンジニアリング、工学寄りの分野です。けれども、自然言語処理分野の人の全員が全員、工学寄りのことをやる必要はないと思っているので、そういう社会科学に対する貢献を意識して、今研究に取り組んでいます。
03
多言語モデルの言語処理能力にも注目
%20(1).webp)
―貴学が今回文系と理系を融合したようなソーシャル・データサイエンス学部・研究科を作られたこと自体、非常に時代の流れを反映していると思います。恐らく、他の時代では全く想像できなかったようなことが起きていると言って良いでしょう。先ほど、小町先生から文章の正しさや品質評価に関するお話をいただきましたが、私は「多言語ゼロショット学習」という革新的な手法が気になります。これも今、研究のテーマとして取り組まれておられるのですか。
そうですね。深層学習(多層のニューラルネットワークを使った機械学習の手法)が登場する前には、それぞれの言語ごとにシステムを作っていました。日本語を処理するシステムでは、英語はできないし、英語でできても、日本語ができないということが多かったのです。一方で、最近の言語モデルは色々な言語を混ぜこぜにして学習していて、それによって、例えば、英語のデータがほとんどであるにも関わらず、日本語のデータを少し入れて学習してやると、日本語でも指示を出すと、日本語で返してくれることが知られています。
「多言語ゼロショット学習」とは、このような深層学習の特徴を利用し、解きたい問題に関連する言語を事前に学習せずに言語横断的に処理できる手法です。最近では、ChatGPTを使われている方が多いのではないかと思いますが、自分の好きな言語でこういうことをしてと指示を出しますよね。それ自身は、もう割と当たり前のアプローチになっていまして、多言語ゼロショット学習とわざわざ言わなくなっている気がしています。
最近注目されている話題としては、多言語とか、多文化ですね。それぞれの言語モデルの中に入っている知識として、例えば日本語や日本文化に関する知識がどういうふうに入っているか、英語や米国やイギリス文化に関する知識がどういうふうに入っていて、それをどういうふうに聞いたら聞き出せるのか。日本の知識を日本語で聞いても英語で聞いても聞き出せるか、とかです。
後は、社会的なバイアスですね。日本語で聞いたら、日本人を採用しやすくなるような、そういうデシジョンをしがちになるとか、逆に英語で聞いたら、日本人が不利になるみたいなことですね。そういう社会的なバイアスがあるのではないかと。これは、先行研究でも言われていて、実際に一橋大学でも、そのようなバイアスがあることを検証する研究を行っています。
04
生成AIが不得意なことを許容する閾値は国や世代で違う
%20(1).webp)
―わかりました。次に技術の現状と限界というフィールドについて、少しお話をお聞きしたいです。もはや生成AIが、かなり一般化していて我々ユーザーというか、学生も含めて、結構ブラックボックス化してしまっているような気がするのですが、今の生成AIですね。ChatGPTのセマンティック的(意味や意味論に関することを指す語)な意味を、どれだけ正確に扱えているか、限界がどこにあるか。先生のお考えではいかがでしょうか。小町先生は、生成文章の品質評価も研究されているので、今の現在地としての生成AIの正確性というのは、小町先生のお立場ではどのように考えられていますか。
生成AIは生成する方にフォーカスが当たっていると思うのですが、実際には人間が指示を、大体は文章で指示すると思います。それをどういうふうに理解するのかということと、その指示を理解してしっかりと処理できるかどうかというところが、5年前と比べると、ものすごく長い量の文章を処理できるようになりました。
それに、昔は画像と音声、テキストは別々に処理されていたのですが、今は全部入れることができます。画像を入れて、「これをジブリ風にしてくれ」と言ったら、それらしく変換できるわけです。それは深層学習のアプローチによる恩恵が大きいと思っています。
一方できないこともあります。例えば、画像を見ても正しそうに見えるものの、細かく見ると箱の一片が合っていないとか、指の本数が6本あるとか…、細かいところはできていないことがあったりします。要約とか翻訳とかでも、ハルシネーション(AIが学習データに存在しない情報をもっともらしく生成する現象)という用語を良く聞かれると思うのですが、元々入力されていないようなものを出してしまうといったことがあると知られています。
特に日本人は、クォリティーにかなり厳しくて、少しでもおかしいところがあると「これは使えない」と言って、すべての用途を否定したりするところがあります。日本は、ものすごく生成AIの利用率が他の国と比べて低いのですが、それはクォリティーに対する厳しさが非常に大きいからだと思っています。一方で、実際にそれを見た時に、細かく見たら確かにおかしいとはいえ、それをあまり気にしなくても良いような用途が、世の中には沢山あったりします。そういうような用途では、もう十分に使えるレベルにあって、世界的には「問題があっても使えれば良いのでは」というような雰囲気の文化もあり、実利主義的な文化のところでは、普通に使っているのではないかと思っています。
なので、色々得意な点、苦手な点があって、そこの苦手な点をどこまで許容するのかというようなところの閾値(境目となる値)が国により違うということです。あとは、世代によっても違ってきます。多分若い世代はもうあまり気にせずに使っているのではないかと思うのですが、世代が上がるに連れて、「こんなのは使えない」と思って使わないということが目立っています。
.webp?width=545&height=727&name=_a_1%20(1).webp)
05
目的に応じて生成文章の評価尺度が変わって来る
%20(1).webp)
―まさに、ChatGPTみたいな生成AIが、遊びの道具化してきていると思います。日本人はやはり正確性を求めるところがあります。一方で、欧米は完璧ではなくても「そういうものだ」と受け入れる許容量、寛容度が非常に高かったりします。実際、企業におけるAIの利用状況を見ると、中国や米国と比較して、日本は大きく離されています。その差が、やはりそういったところに出ているのでは思ったりします。次に品質評価に関する課題をお聞きしたいのですが、小町先生が取り組まれている生成文章の品質評価における評価尺度は、どういうふうに設計されているのですか。
それは最終的にどういうことをやりたいのかによって、重視するべき観点が異なってきます。例えば、翻訳では妥当性と流暢性という尺度が典型的によく言われます。例えば日英翻訳だと、英語として流暢かどうかを評価するのが流暢性なのですが、これは元の日本語がどういう文であったのかは、全く関係ありません。英語として、ネイティブが書いたぐらい流暢なのか、それともノンネイティブが書いたようなぎこちない表現なのか、そもそも英語ですらないみたいなレベルなのかが、流暢性の評価となってきます。一方、妥当性というのは、もともとの日本語の意味を英語でもどれぐらい表現できているのかを評価することです。出力はぎこちなくても、日本語で言っていることが全部表現できているとなれば、それはそれでOKですし、英語としては流暢であっても全然違う文を言っているのであれば、妥当性はゼロという、そういうやり方です。
これは翻訳なのでこういう評価尺度でやっているのであって、例えば要約だったら、また違ってきます。そもそも、要約しようと思ったら文章の長さが短くなるのは当然なので、全く同じ意味は表現できません。意味が同じではないことを前提として、どれぐらい元の文章の意味を保持しているのか、というようなことを評価したりします。流暢性の評価もするのですが、そういうようにタスクごとに重視する観点に違いがあります。
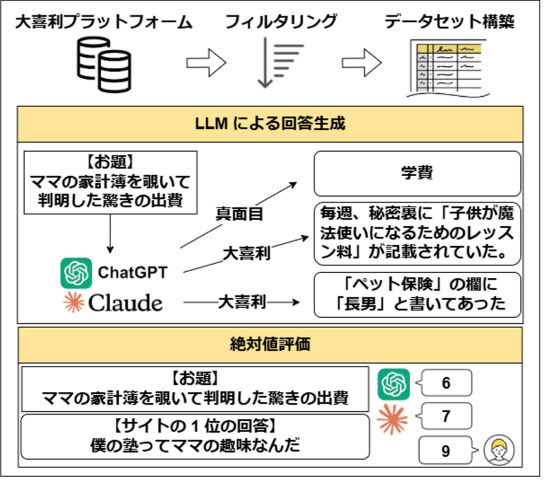
直近、私の研究室で取り組んでいるのは、大喜利の評価です。大喜利はお題があって、それに対してどういうふうに面白く言うかみたいな言葉遊びです。それに関して、これも色々な評価尺度があると思うのですが、ネタがどれぐらいわかりやすいか、あとは、ウィットに富んでいるかとか、共感できるか、みたいな、自分も「あるある」と思えるかどうかみたいな幾つかの尺度があります。全体としては6つの観点で評価しています。
どういうことをしたいかによって、どの観点を見るのかが違っていて、翻訳や要約であれば別に面白くなくても良いわけですが、クリエイティブな生成であればあるほど、真面目すぎて面白くないとかもあるので、多少はずれている方が面白いというのもあります。なので、最終的に何がやりたいのかによって、どういう評価をするべきかが変わってきます。
06
日本は国を挙げて取り組まないと米国や中国に太刀打ちできない
.webp)
―小町先生の最新の著書『自然言語処理の教科書』(技術評論社)を拝見させていただきました。その中で私が一番興味を持ったのが、言語資源(辞書やコーパス)の作り方でした。それに関連して、次に言語の文化と資源の問題を質問させていただきたいです。英語や中国語は、言語的にはかなり豊富だと思うのですが、日本語やその他の少数言語のデータ不足がもたらす問題について、小町先生はどのようにお考えになられますか。
非常に重要な問題だと思っています。世界的にも英語を使っている人が英語ネイティブという意味では特にないのですが、英語を中心に進むことが多いです。世の中にあるデータも、英語が多いというのもあります。
ただし、実は日本語もそんなに少なくはなかったりします。日本にいると、少ないように見えるかもしれませんが、少なくともトップテンに入るぐらいリソースがある言語です。とはいえ、英語と比べると1桁、2桁違うという問題があるのは事実です。日本の人たちが日本語に関して、何か質の高い処理をしようと思うと、日本独自のものを作った方が良いというような形になります。
国立情報学研究所に、大規模言語モデル研究開発センターがあります。そこを中心に日本全国が協力して開発を進めており、そこで得た知見は全部オープンにするという前提で、企業も入ってやっています。そういうふうに国を挙げて取り組まないと、全然太刀打ちできない状況にあります。何しろ、中国や米国が生成AIに投下している金額は莫大ですからね。日本は予算的にも、人材のプール的にもそこまでできません。
だからといって、何もしなくて良いのかというとそれは違います。確かに日本独自でやらなくてもOpenAIが作ったChatGPTやGoogle の生成AIモデルGeminiをカスタマイズして使えば良いのでは、という形になることも、産業的には全く問題ないと思うのですが、安全保障的な観点も見逃してはいけません。突然、中国と緊張関係になったり日米関係が悪化して、クローズな大規模言語モデルに対するアクセスが遮断されたとなった瞬間に、色々なビジネスが麻痺したりする可能性があります。そういうことを考えると、日本は日本で独自の技術をある程度、キャッチアップしていかないといけなくなります。
実際に大規模言語モデル研究開発センターでは大規模言語モデルの開発をするグループがあって、最先端の2年遅れぐらいでついていけているので悪くないと言えます。むしろ、日本に関しては、この辺りの政策や動きが非常に上手く進んでいると個人的には思っています。下できる人的資源や予算も世界で奪い合いなのですが、それらを考慮した上でやれる中では、ものすごく上手くやっていると思っています。
07
文化資源が膨大な英語。限られている日本語
%20(1).webp)
―おっしゃる通りですね。やはり、安全保障の問題は多くの先生方や企業の方も指摘されます。どうしても米国でChatGPTや次世代AI(人工知能)モデル「GPT-5」が出たりして、ファインチューニング(事前に学習済みのモデルを目的のタスクに合わせて追加学習する手法)することによって、それを活用することができますけれど、もし本当に日米関係が急変したらどうなるのか、中国のDeepSeek(ディープシーク)(中国のAI企業が開発したオープンソースの高性能AIツール)だとやはり「国防上まずいのでは」という判断が避けられませんからね。もう1点、言語の文化資源の問題でお聞きしたいと思います。言語というのは、やはり文化的背景を非常に反映しているものだと思います。言語だけをファインチューニングだったり、学習したりするだけだったら良いのですが、文化という目に見えるのか見えないのか分からないものを、どういうふうに言語生成の中に入れていくのか、もしくは翻訳をしていくのか。小町先生は、どのようにお考えになりますか。
これも結構難しい問題です。インターネット上とかに公開されているデータがどれぐらいあって、それを含めたデータがどれぐらい学習に使えるかという話だと思っています。英語に関して言うと、かなりウェブ上にデータがあります。YouTubeの動画データもそうなのですが、沢山あるので、我々人間が生きている中で色々な経験をして学んでいるようなことはある程度ウェブ上に載っています。人間が経験するよりはるかに長時間の動画とか、人間が1人ではとても読み切れないようなものを使って学習できているので、数の暴力によってある程度できる状態になっていると思っています。
一方、日本語や日本文化に関して言うと、英語ほどそんなに特に何か動画を使ったりしないと分からないようなものに関してのリソースが少ないです。沢山あれば我々、身体を持った人間が経験しているようなものも、理解できるのかもしれないのですが、どうしてもないのでできないという状況になっていると思っています。
言語資源のお話を先ほどもしましたが、最近の大規模言語モデルは色々なモデルの重み、ウェイトを公開して他の国の人とかが使えるようにする戦略を取る企業が沢山あります。しかし、結局、その裏側のデータはほとんどの企業で公開していません。日本でも、幾つかの大企業がモデルを公開していますけれど、裏側で使っているデータはクローズドです。基本的に大企業であればあるほど、データを作るノウハウを持った人が裏側にいます。ただし、その人たちが外に出てくることは、あまりないのが実態です。
先ほど、大規模言語モデル研究開発センターは知見をすべてオープンにすることになっていると言いましたが、OpenAIやGoogleのような企業の中でトップを走ろうと思っている人たちは、そこには参加せず、データも出さずに独自に取り組んでいます。しかし、それはある意味当然です。そこが虎の子だからです。そこを公にしてしまったら、本当に全部再現されてしまいます。そういうデータの囲い込みによって、他の企業や組織と比べてリードタイムを稼ごうとしているわけです。OpenAIも少なくとも1年、2年先を行っているのではないかと思っています。そこはやはり中で持っているデータを公開してしまうと、色々なものが真似をされてしまい、競合他社に負けてしまいますからね。
08
生成文章を評価する重要性がようやく理解されつつある
%20(1).webp)
―言語資源の作り方とかでも指摘されているように、言語を生成する、作っていく過程を研究されていると思います。これは、日本語に特化しているのですか。それとも、汎用的なもので考えられているのですか。
最近は、日本語に特化したようなやり方でやらないことが増えています。というのも、大規模モデルで色々な言語を混ぜこぜにしてやれるようになっているからです。それに、日本語に特化したようなことを作り込んでしまうと、他の言語で使いにくくなってしまうという問題もあります。もう完全に日本の市場だけをターゲットにしている場合には、作り込むこともできるのですが、必ずしもそれが良いとは限りません。
言語資源を作り込む人は、ものすごく人数が少ないです。評価データを作らないと、自分の作った手法が良いか悪いかの評価もできません。そこをいい加減にやってしまうことが、自然言語処理の歴史の中では多かったのです。
一方、ここ3年ぐらいを考えてみると、データを用意して色々な言語で色々なタスクで評価して、「全体的にこっちの言語モデルの方が良い」みたいな評価をするように業界が変わってきたので、評価の重要性を皆が漸く分かってきたのかなと思っています。ベンチマークデータセット(機械学習において、特定のアルゴリズムやモデルの性能を公正かつ再現可能な方法で評価・比較するために使用される、標準的なデータセット)が公開されて誰でも使えるようになってきたのは、とても良いことだと思います。
_%E3%82%AD%E3%83%BC%E3%83%93%E3%82%B8%E3%83%A5%E3%82%A2%E3%83%AB.webp)

Pick up!
_%E3%82%AD%E3%83%BC%E3%83%93%E3%82%B8%E3%83%A5%E3%82%A2%E3%83%AB2_2x.webp)
